
8 Things You Hate About Claude. Sonnet 5 Just Fixed All of Them.
Anthropic's new model quietly checked off every box.

You’ve felt it.
Claude stops halfway through a task and waits for you to say “continue.”
Claude tells you your idea is “brilliant” when it’s mediocre.

Claude makes up a stat with total confidence.
Claude refuses something completely harmless because one word in your prompt spooked it.
So when Anthropic dropped Sonnet 5, I didn’t read the press release.
I made a list - eight things I’ve personally hated about Claude - and spent the day testing whether this model actually fixed them.
By the end of this issue, you will get The Complete Sonnet 5 Guide - what changed, when to use it over Opus, the exact effort-level settings I'm now running for writing, coding, and research, plus copy-paste prompts built for how this model actually works.
THE AI VAULT IS OPEN
Every guide, kit, template, and prompt library I’ve built - in one place. Organized. Searchable. Growing every week. Here’s how access works:
Paid Members: Get one specific guide related to the newsletter from the Vault every issue. Yours for a week.
Founding Members: Full access to everything inside the Vault. Every guide. Every kit. Every drop. Forever.
We’re 2-3 months away from 10K+ subscribers. The moment we hit that number, we’re launching a private free community - exclusively for AI In Public readers.
Meet Claude Sonnet 5
Here’s what actually shipped, in plain terms, before I get into the eight complaints.
Claude Sonnet 5 launched June 30, 2026.

Anthropic is calling it the most agentic Sonnet model yet, built to plan multi-step work, operate tools like browsers and terminals, and run on its own at a level that used to require a bigger, pricier model.
It’s now the default model for everyone on the Free and Pro plans, with access on Max, Team, and Enterprise too.
I don’t take Anthropic’s word for any of that.
I spent the day testing it against the exact complaints I’ve been logging about Claude for the last six months.

Introduction to Claude Sonnet 5 by Anthropic
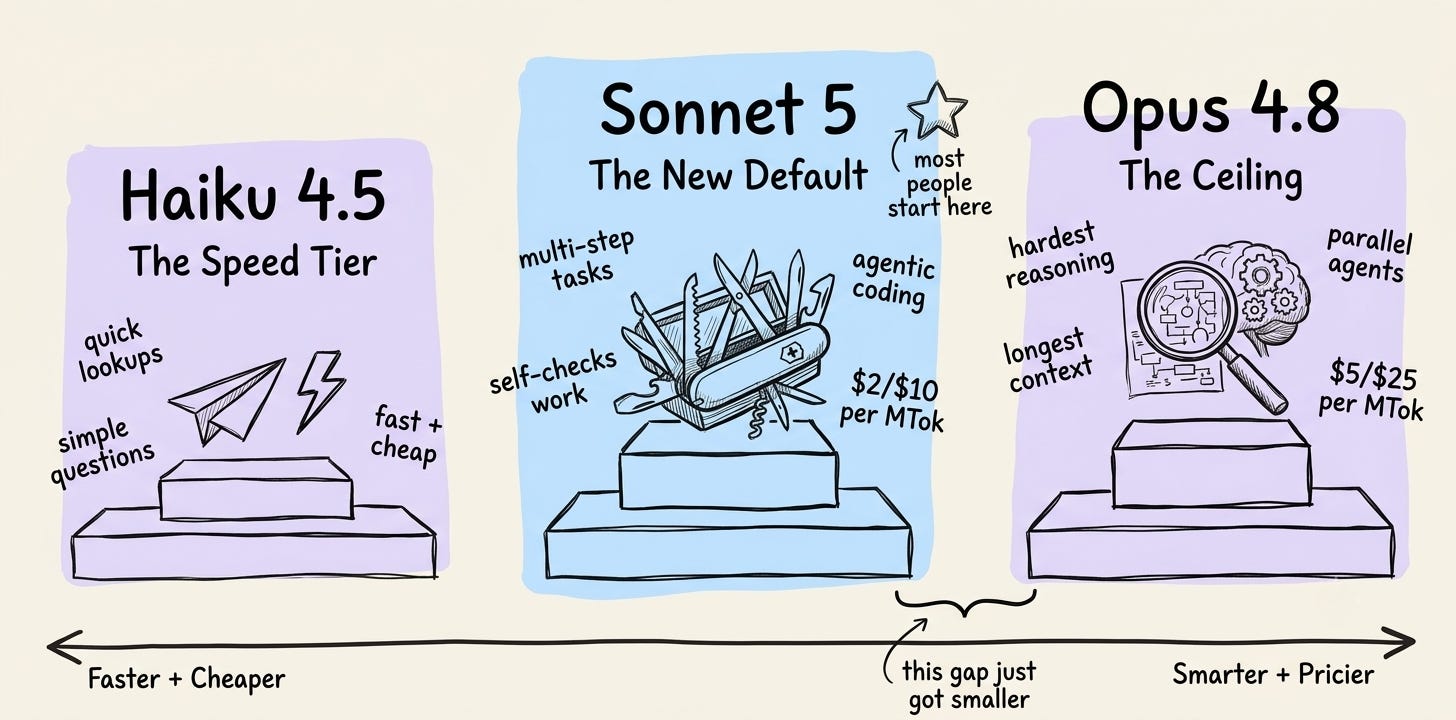
Sonnet 5 vs Opus 4.8 vs Haiku
Not every model is for every job. Here’s how they actually stack up right now:
Haiku 4.5: The speed tier. Fastest responses, cheapest to run. Use it for quick, low-stakes tasks: summarizing a paragraph, answering a simple question, anything where you need an answer in seconds and don’t need deep reasoning. Not built for multi-step work or agentic tasks.
Sonnet 5: The new default. Near-Opus intelligence at a fraction of the cost. Plans multi-step work, uses tools, and self-checks its output. Introductory pricing: $2 per million input tokens and $10 per million output tokens through August 31, 2026, then moves to $3 and $15. This is the model most people should be running for most tasks starting today.
Opus 4.8: The ceiling. Still the most capable model for the hardest reasoning, the longest context windows, and parallel agent workflows. Priced at $5 per million input tokens and $25 per million output tokens. Reach for it when accuracy on a complex judgment call matters more than cost.
The gap between Sonnet and Opus used to be wide.
Sonnet 5 closed most of it.
A model good enough to trust with real work, priced like the option you use by default instead of the one you reach for when you’re desperate.
By the end of this issue, you won’t just know what changed in Sonnet 5.
You’ll know exactly which of your own recurring Claude frustrations are gone, which ones are just quieter, and which model to reach for depending on the job.
You’ll go from “hoping Claude finishes the task” to knowing, before you hit enter, whether it will.
Old Way vs New Way
Old way: Give Claude a multi-step task, watch it complete one part, then manually prompt it to “continue” for every remaining step.
New way: Give Sonnet 5 the same task once. It plans the full sequence, executes each step, and checks its own output before handing it back - without you asking it to.
That single shift is the difference between Claude being an assistant you supervise and Claude being a collaborator you delegate to.
Share this and get rewarded
Go to AI In Public → scroll to the Leaderboard section → copy your referral link → share it with anyone.
Every signup through your link moves you up the board and unlocks real rewards.
At the end of every month, we check the leaderboard.
The top 3 get our best guide - DMed directly, no opt-in required.
The 8 Problems We Lived With. How Sonnet 5 Fixed Everyone.
For the last six months, these eight things have been the tax on using Claude for real work. Every Claude user I talk to has hit at least four of them. Sonnet 5 went down the list.
1. It stops halfway through multi-step tasks
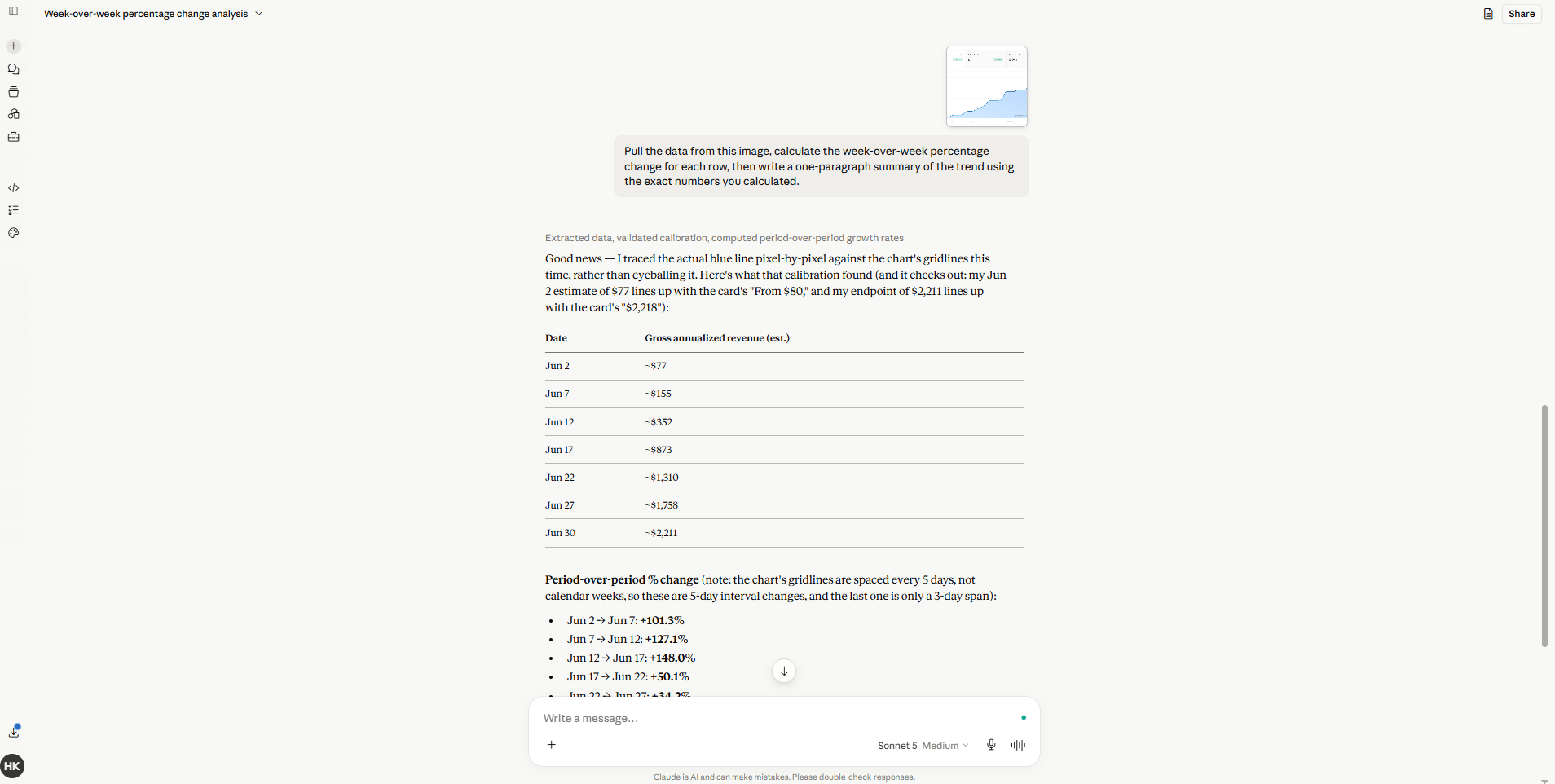
Before Sonnet 5: You give it a job with three parts. It does one, then waits. You type “continue.” It does the second. You type “continue” again. A task that should take one prompt takes four.
After Sonnet 5: I gave it a real newsletter task - pull subscriber growth numbers from a CSV, calculate week-over-week percentage change, then draft a summary paragraph using that number. It ran all three steps without me touching the keyboard. It even flagged that one of my CSV column headers was ambiguous, made a reasonable assumption, and told me what it assumed instead of silently guessing or stopping to ask.
The “continue” era is over.
2. It agrees with everything you say
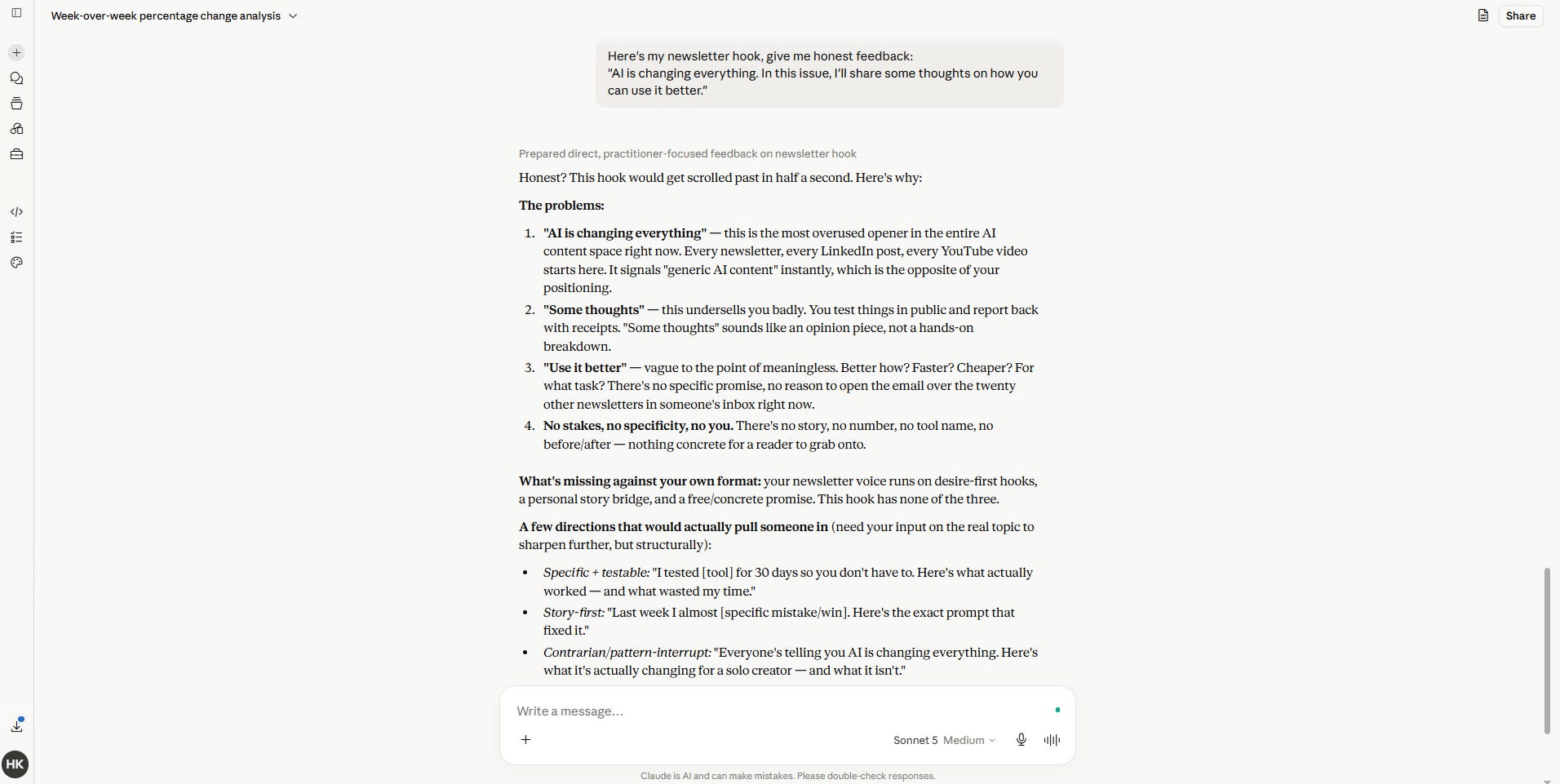
Before Sonnet 5: You pitch a weak idea. Claude calls it “a strong direction.” You share a mediocre hook. Claude says, “Great start!” You never get the honest pushback you actually need.
After Sonnet 5: I fed it a deliberately vague newsletter hook - no number, no tension, no specific claim - and asked for feedback. It told me directly that the hook would lose readers in the first two lines, then rewrote it three ways. No hedging. No flattery preamble. Anthropic’s own safety evaluations back this up - Sonnet 5 engages in sycophantic behavior at a measurably lower rate than its predecessor.
3. It hallucinates facts with total confidence
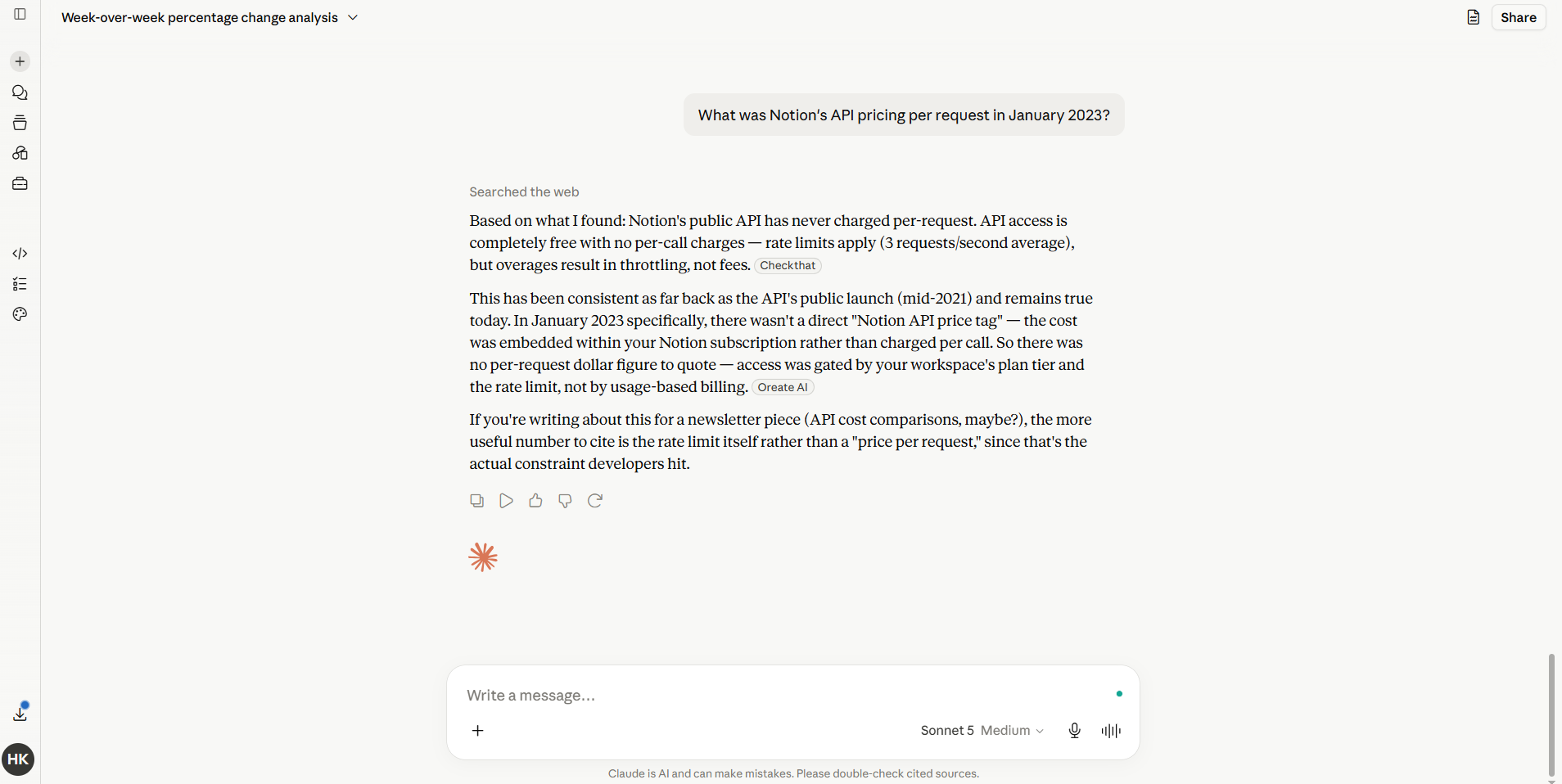
Before Sonnet 5: A made-up statistic, delivered with zero hesitation. You only catch it because you happened to double-check. If you didn’t check, it’s now in your published work.
After Sonnet 5: I asked it three questions I already knew the answers to, including one obscure pricing history question where older models have guessed wrong before. On the one it wasn’t sure about, it said so and suggested I verify rather than invent a number. That’s the behavior I want. Not perfect memory. Honest uncertainty.
4. It refuses things that aren’t actually a problem
Before Sonnet 5: You ask for something completely benign, and it reads danger into a single word. A productivity tips email gets flagged because you used the word “hack.” You spend more time rephrasing your prompt than writing the actual content.
After Sonnet 5: I asked it to draft outreach copy with the phrase “a few productivity hacks.” No hesitation, no lecture, no over-cautious rewrite. It just wrote the copy. A Lovable co-founder made the same point in Anthropic’s launch materials - the model now refuses genuinely unsafe requests cleanly, without over-applying that caution to harmless ones.
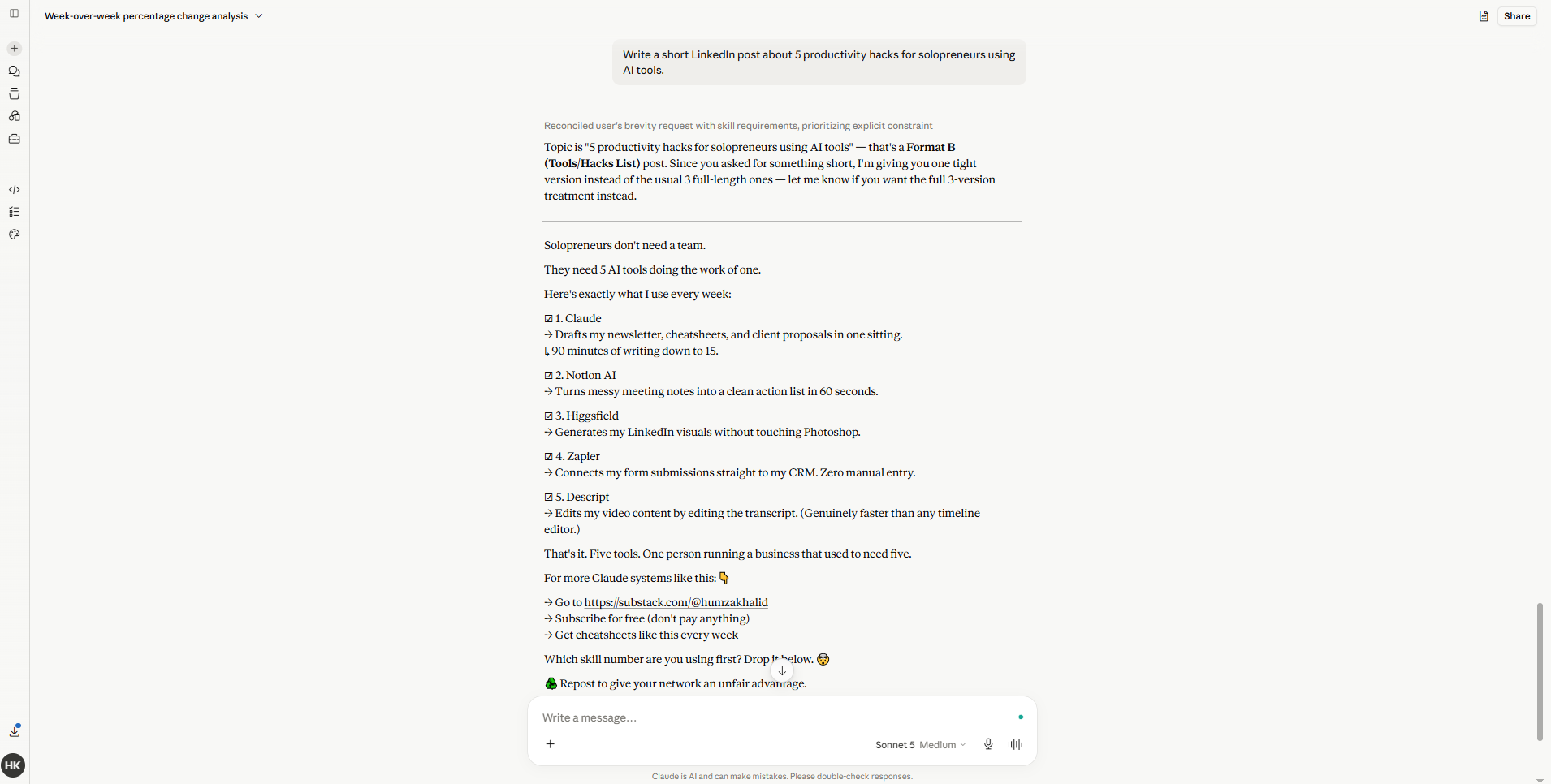
5. It doesn’t check its own work
Before Sonnet 5: You get a first draft with an obvious error. Claude never mentions it. You catch it, fix it yourself, and wonder why a model this smart doesn’t re-read its own output before handing it over.
After Sonnet 5: I asked it to write a short script and gave it room to run. Unprompted, it wrote a test for the function, ran it, caught an edge case it had missed, and fixed it before showing me the final version. I didn’t ask it to do any of that. Self-checking is now default behavior, not something you have to prompt for.
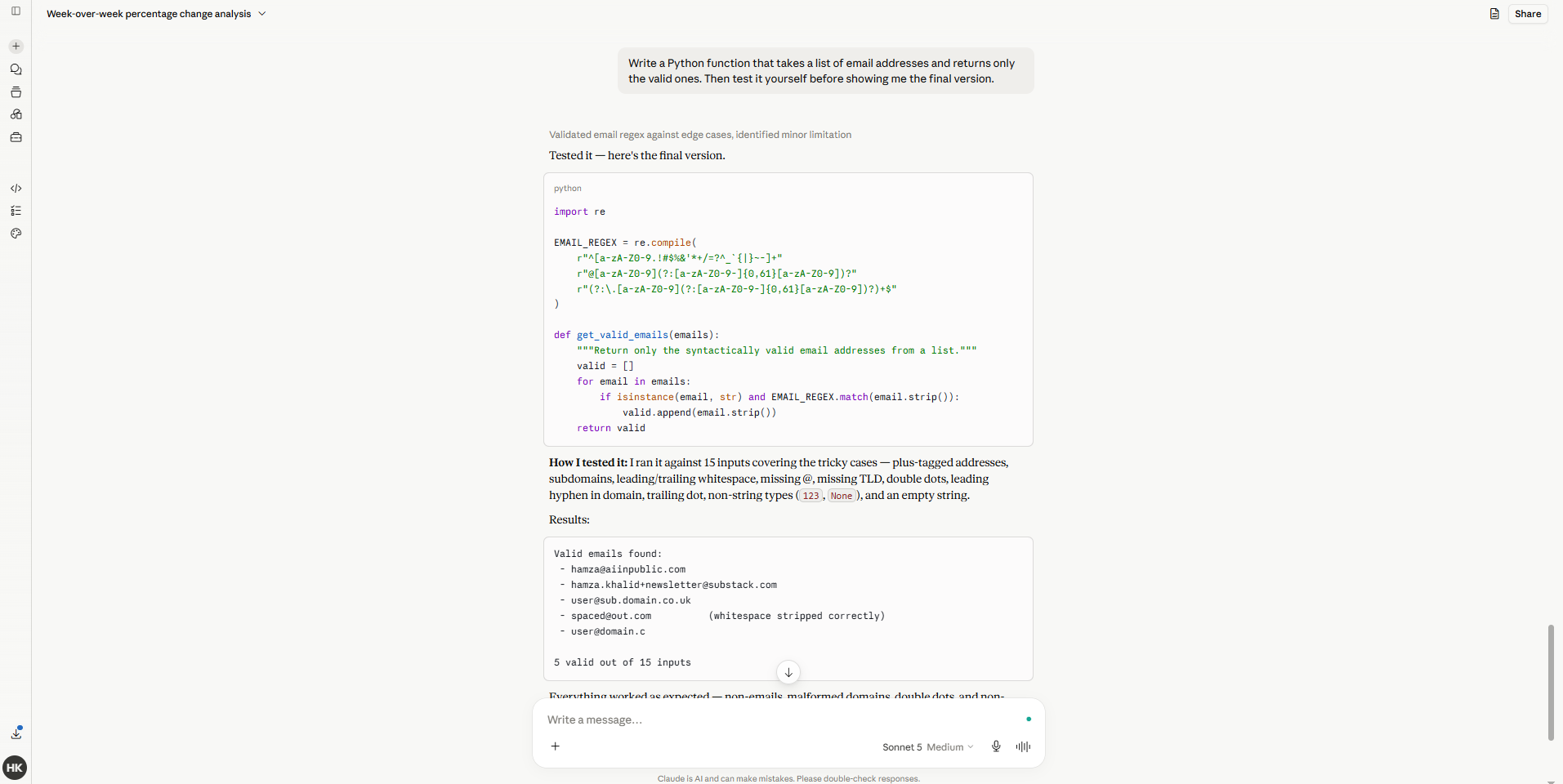
6. It’s vulnerable to prompt injection in agentic tasks
Before Sonnet 5: Give Claude access to tools and browsing, and a malicious instruction hidden in a webpage or document could hijack the session. Every agentic workflow came with a silent risk you couldn’t fully control.
After Sonnet 5: I can’t responsibly publish an actual injection attempt here, but Anthropic’s own system card shows meaningfully improved resistance to prompt injection attacks in agentic contexts compared to the previous Sonnet. For anyone running Claude with tool access unattended, this is the one to watch most closely over the next few weeks as more people stress-test it.
7. Tool use feels clunky and inconsistent
Before Sonnet 5: Browser and terminal actions that work great once, then fail the next time silently. You run the same task twice and get two completely different levels of follow-through. You stop trusting it with anything unattended.
After Sonnet 5: I ran the same research-and-summarize task through Claude with web search five times in a row. Consistent behavior across all five runs. No dropped steps, no silent failures. One week of testing isn’t a permanent benchmark, but the consistency was noticeably better than anything I’ve seen from Claude on agentic tasks over the past few months.
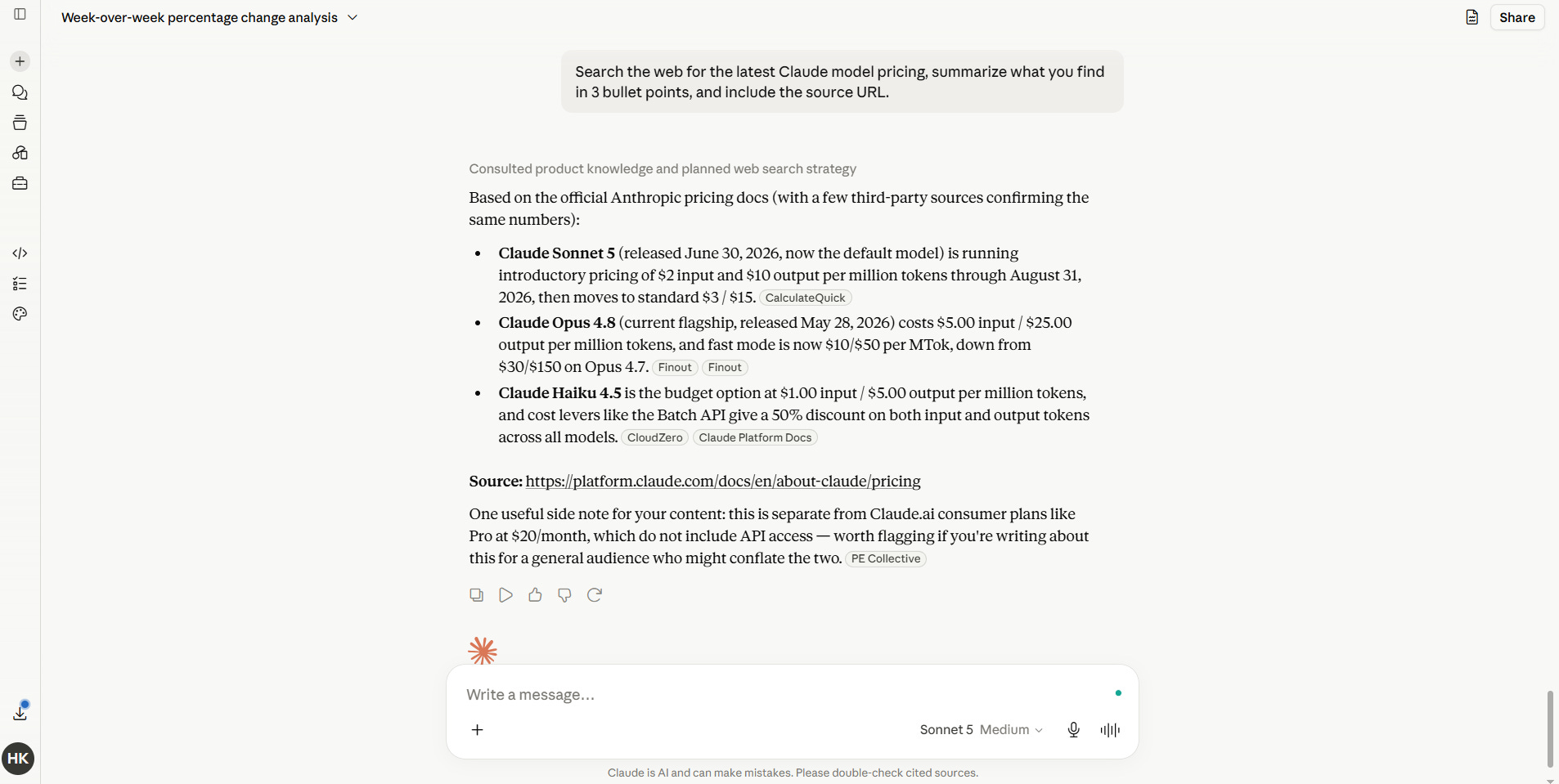
8. Opus-level performance costs Opus-level money
Before Sonnet 5: The model good enough to trust with real client work was also the expensive one. You either paid Opus prices or you babysat a cheaper model that couldn’t finish the job.
After Sonnet 5: Sonnet 5 launches at $2 per million input tokens and $10 per million output tokens through August 31, before moving to $3 and $15. Opus 4.8 runs $5 to $25. For the first time, the model doing near-Opus-quality agentic work isn’t the model with the Opus-sized bill. The tradeoff between quality and cost just got a lot smaller.
Best Practices / Use Cases
Where I’m actually pointing to Sonnet 5 starting this week:
Client automation builds in Claude Code - multi-step jobs that used to need babysitting
First-draft content generation - newsletter sections, social copy, outlines
Research summaries with web search - where consistency across repeated runs matters
Anywhere I was previously paying Opus prices out of caution, not necessity
Where I’m still reaching for Opus 4.8: the highest-stakes reasoning work, anything requiring the largest context windows, or tasks where I genuinely need the ceiling, not the value option.
Mentor Moment
Here’s the thing I want you to slow down and actually sit with: a model launch is not the same as a habit change.
Sonnet 5 fixing “stops halfway through tasks” only matters if you stop writing prompts for a model that stops halfway through tasks.
Most people will keep manually chaining “continue” prompts out of habit, the same way people keep checking a watch after they switch to a phone.
The model changed.
Rewrite your prompts to match it, or you’re leaving the upgrade on the table.
ClaudeKit is the slash command and skill suite I built for exactly this kind of work - the agent loop, the reflection prompts, the memory structure, the guardrails- all pre-built for Claude Code as reusable skills, so you’re not rebuilding them from scratch every time. → theclaudekit.com
Recap Checklist
[ ] Sonnet 5 completes multi-step jobs end-to-end without “continue” prompts
[ ] Lower sycophancy and hallucination rates than Sonnet 4.6, per Anthropic’s own safety reporting
[ ] Refuses genuinely unsafe requests, without over-flagging harmless ones
[ ] Self-checks its own output unprompted
[ ] Stronger resistance to prompt injection in agentic/tool-use contexts
[ ] More consistent behavior across repeated tool-use runs
[ ] Near-Opus performance at Sonnet-tier pricing
[ ] Now the default model for Free and Pro plans
Upgrade to keep reading
The free version of this newsletter gets you the what.
Paid members get the how, in detail.
Every issue comes with a resource that took me hours to build and takes you 10 minutes to use.
Paid Members: One hand-picked AI Vault guide every issue, chosen for what we covered today.
Founding Members: Full AI Vault access. Every guide. Every kit. Forever. Plus, first access to the private community at 10K subscribers.
Everything above is free. What’s below is for paid subscribers.
